Create your first LLM playground
Create a playground to evaluate multiple LLM Providers in less than 10 minutes. If you want to see this in prod, check out our website.
What will it look like?
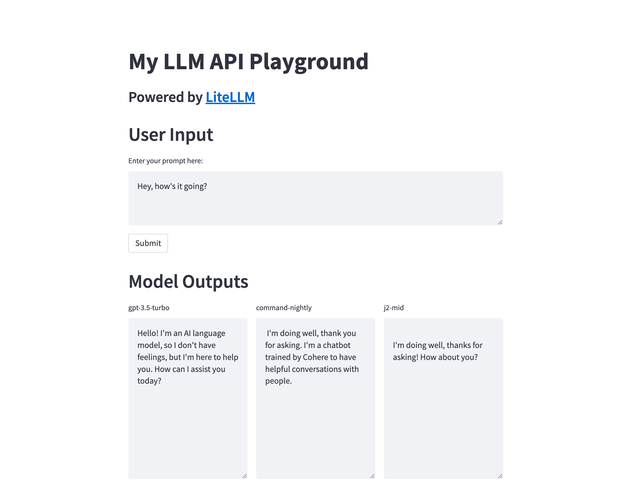
How will we do this?: We'll build the server and connect it to our template frontend, ending up with a working playground UI by the end!
Before you start, make sure you have followed the environment-setup guide. Please note, that this tutorial relies on you having API keys from at least 1 model provider (E.g. OpenAI).
1. Quick start
Let's make sure our keys are working. Run this script in any environment of your choice (e.g. Google Colab).
🚨 Don't forget to replace the placeholder key values with your keys!
pip install litellm
from litellm import completion
## set ENV variables
os.environ["OPENAI_API_KEY"] = "openai key" ## REPLACE THIS
os.environ["COHERE_API_KEY"] = "cohere key" ## REPLACE THIS
os.environ["AI21_API_KEY"] = "ai21 key" ## REPLACE THIS
messages = [{ "content": "Hello, how are you?","role": "user"}]
# openai call
response = completion(model="gpt-3.5-turbo", messages=messages)
# cohere call
response = completion("command-nightly", messages)
# ai21 call
response = completion("j2-mid", messages)
2. Set-up Server
Let's build a basic Flask app as our backend server. We'll give it a specific route for our completion calls.
Notes:
- 🚨 Don't forget to replace the placeholder key values with your keys!
completion_with_retries: LLM API calls can fail in production. This function wraps the normal litellm completion() call with tenacity to retry the call in case it fails.
LiteLLM specific snippet:
import os
from litellm import completion_with_retries
## set ENV variables
os.environ["OPENAI_API_KEY"] = "openai key" ## REPLACE THIS
os.environ["COHERE_API_KEY"] = "cohere key" ## REPLACE THIS
os.environ["AI21_API_KEY"] = "ai21 key" ## REPLACE THIS
@app.route('/chat/completions', methods=["POST"])
def api_completion():
data = request.json
data["max_tokens"] = 256 # By default let's set max_tokens to 256
try:
# COMPLETION CALL
response = completion_with_retries(**data)
except Exception as e:
# print the error
print(e)
return response
The complete code:
import os
from flask import Flask, jsonify, request
from litellm import completion_with_retries
## set ENV variables
os.environ["OPENAI_API_KEY"] = "openai key" ## REPLACE THIS
os.environ["COHERE_API_KEY"] = "cohere key" ## REPLACE THIS
os.environ["AI21_API_KEY"] = "ai21 key" ## REPLACE THIS
app = Flask(__name__)
# Example route
@app.route('/', methods=['GET'])
def hello():
return jsonify(message="Hello, Flask!")
@app.route('/chat/completions', methods=["POST"])
def api_completion():
data = request.json
data["max_tokens"] = 256 # By default let's set max_tokens to 256
try:
# COMPLETION CALL
response = completion_with_retries(**data)
except Exception as e:
# print the error
print(e)
return response
if __name__ == '__main__':
from waitress import serve
serve(app, host="0.0.0.0", port=4000, threads=500)
Let's test it
Start the server:
python main.py
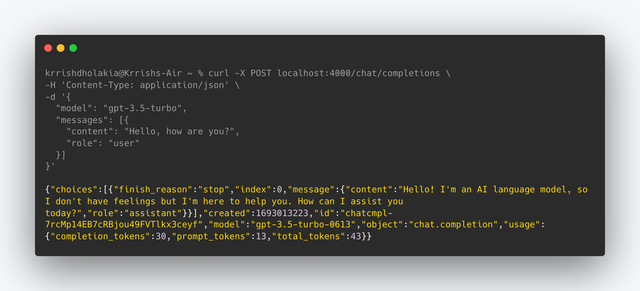
Run this curl command to test it:
curl -X POST localhost:4000/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{
"content": "Hello, how are you?",
"role": "user"
}]
}'
This is what you should see
3. Connect to our frontend template
3.1 Download template
For our frontend, we'll use Streamlit - this enables us to build a simple python web-app.
Let's download the playground template we (LiteLLM) have created:
git clone https://github.com/BerriAI/litellm_playground_fe_template.git
3.2 Run it
Make sure our server from step 2 is still running at port 4000
If you used another port, no worries - just make sure you change this line in your playground template's app.py
Now let's run our app:
cd litellm_playground_fe_template && streamlit run app.py
If you're missing Streamlit - just pip install it (or check out their installation guidelines)
pip install streamlit
This is what you should see:
Congratulations 🚀
You've created your first LLM Playground - with the ability to call 50+ LLM APIs.
Next Steps: